
Mục lục
1. Giới thiệu: SGA là gì?
Như bạn đã biết ở bài học trước, SGA là phân vùng chia sẻ trên Memory, nó lưu trữ các dữ liệu được chia sẻ cho toàn bộ người dùng.
Trong bài học này các bạn sẽ được biết thêm bên trong SGA còn có những thành phần con khác với những vai trò riêng. Bây giờ chúng ta sẽ cùng tìm hiểu nhé
2. Thành phần đầu tiên: Shared Pool
Thành phần đầu tiên trong SGA mà tôi muốn nói tới, đó là Shared Pool.
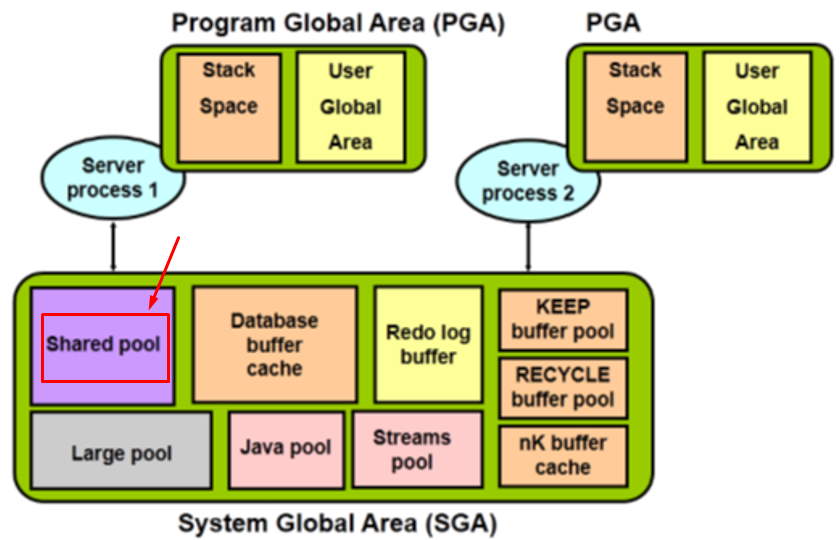
Giả sử bây giờ các bạn thực hiện một câu lệnh như sau:
select id, name from khach_hang;
Đầu tiên câu lệnh đó sẽ được nạp vào Shared Pool, chính xác hơn là phân vùng Library Cache thuộc Shared Pool. Sau đó Oracle sẽ thực hiện phân tích câu lệnh đó, nó sẽ kiểm tra các bước sau:
- Nó sẽ kiểm tra về mặt cú pháp, về cấu trúc của câu lệnh về các đối tượng thành phần mà câu lệnh có tác động. Giống như khi bạn được người khác hỏi đường đến Hồ Gươm chẳng hạn, thì bạn cần phân tích lời của người hỏi để biết đường mà trả lời.
- Và để trả lời cho người hỏi, bạn cần phải lục lại kiến thức đường xá của bạn ở đâu đó chứ, phải không?
- Có thể bạn biết vị trí đó, thì bạn có thể lục trong bộ nhớ của bạn, hoặc nếu bạn không biết chỗ đó, nhưng bạn lại có 1 chiếc smart phone trong tay, vậy bạn có thể mở Google Map ra. Oracle Database cũng như vậy, nó sẽ có 1 cuốn sổ tay ghi lại tất cả những thông tin mà nó nắm được bên trong database. Ví dụ:
- Trong database có những bảng gì?
- Trong bảng có những cột gì?
- Bảng này do ai sở hữu?
- Bảng này có index không?
- …
Cuốn sổ tay này có tên gọi là data dictionary (và nó cũng thuộc Shared Pool)
Sau khi đã biết đầy đủ các thông tin về Hồ Gươm rồi, bộ não chúng ta sẽ xử lý, làm thế nào để đi tới đó?
- Đi Tây Sơn, Chùa Bộc rồi đi đường phố Huế lên?
- Hay đi Nguyễn Chí Thanh, đi đường Kim Mã, Nguyễn Thái Học?
Bộ não sẽ xử lý để lựa chọn con đường đi tốt nhất
Một lần nữa, Oracle cũng lại như vậy. Nó sẽ tính toán dựa trên các thông tin mà nó có để xác định con đường lấy dữ liệu tốt nhất. Con đường đó gọi là Execution Plan. Đây là 1 ví dụ về Execution Plan:
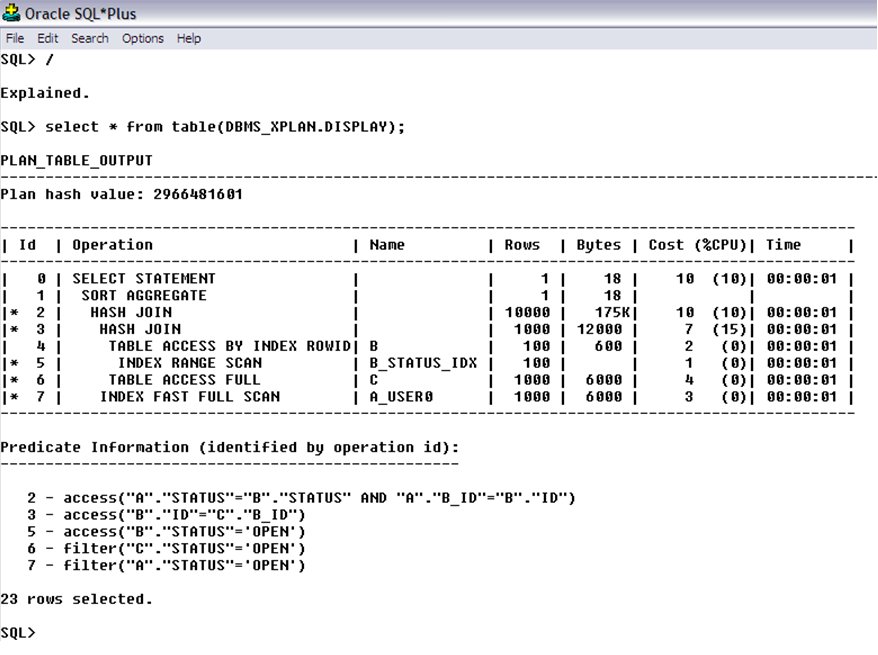
Execution Plan này sau khi được phân tích sẽ lại được lưu lại trong Library Cache, để lần sau có ai chạy lại câu lệnh như thế nữa thì khỏi phải phân tích gì nữa, chỉ đường đi luôn!
3. Thành phần thứ 2: Database Buffer Cache
Thành phần tiếp theo trong SGA, đó là Database Buffer Cache.
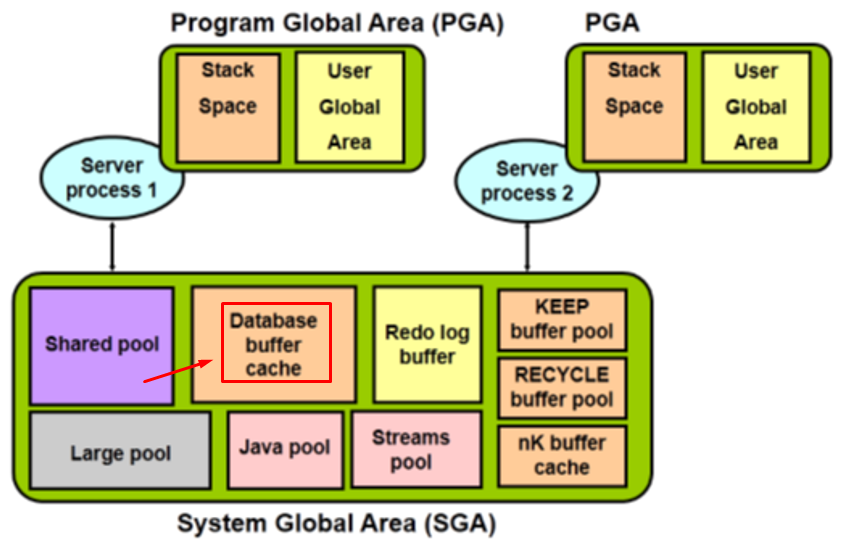
Khi bạn thao tác với dữ liệu, ví dụ như bạn thực hiện lệnh Update chẳng hạn: Dữ liệu cần cho câu lệnh Update đó sẽ phải nạp lên Memory để xử lý, chứ không trực tiếp thao tác trực tiếp dưới ổ đĩa.
Nguyên nhân là bởi nếu tất cả người dùng trong database đều làm như vậy thì không ổ đĩa nào có thể chịu được lượng truy cập liên tục như vậy cả!
Giải pháp tốt hơn đó là nạp những dữ liệu mà người dùng cần lên trên Memory, và chia sẻ nó với tất cả người dùng đang kết nối vào. Như vậy thì chúng ta sẽ chỉ cần đọc dữ liệu từ dưới đĩa lên một lần, những lần sau chúng ta sẽ đọc dữ liệu ở trên Memory.
Như vậy thì trên Memory cần phân hoạch một khu vực có nhiệm vụ lưu trữ các dữ liệu được đọc từ dưới ổ đĩa lên. Khu vực đó hẳn các bạn đã đoán ra: Database Buffer Cache.
Quy trình đầy đủ sẽ như sau: Bạn cần thao tác với 1 dữ liệu (SELECT, UPDATE, …). Oracle Database sẽ kiểm tra ở trên Database Buffer Cache xem đã có dữ liệu cần thiết hay chưa?
Nếu chưa có nó sẽ đọc dữ liệu đó từ ổ đĩa lên và nạp vào Buffer Cache.
Từ những lần sau trở đi, dữ liệu sẽ được đọc từ Buffer Cache chứ không đọc từ dưới ổ đĩa lên nữa. Tiết kiệm thời gian hơn nhiều.
Khi bạn thay đổi dữ liệu đó trên Buffer Cache, dữ liệu sau khi sửa cũng không ghi ngay xuống dưới đĩa, nó sẽ được đánh dấu là dirty buffer, và đợi cho đến khi có 1 tiến trình ghi nó xuống (Tiến trình gì thì chúng ta sẽ tìm hiểu ở bài khác nhé).
Các dữ liệu đã nằm trên Buffer Cache không phải là nó cứ ở đó mãi. Thế thì đầy Buffer Cache rồi, dữ liệu mới làm sao mà lên được. Oracle xử lý điều này bằng 1 thuật toán gọi là LRU (least recently used), nó sẽ đánh giá các dữ liệu trên Buffer Cache, và đẩy chúng vào 1 hàng đợi, dựa trên thứ tự ưu tiên (Cái nào không cần nữa thì đưa vào đầu hàng đợi), rồi lần lượt ghi xuống đĩa.
4. Thành phần cuối cùng: Redo Log Buffer
Phân vùng cuối cùng ở trong SGA trong bài viết này, đó là Redo Log Buffer.
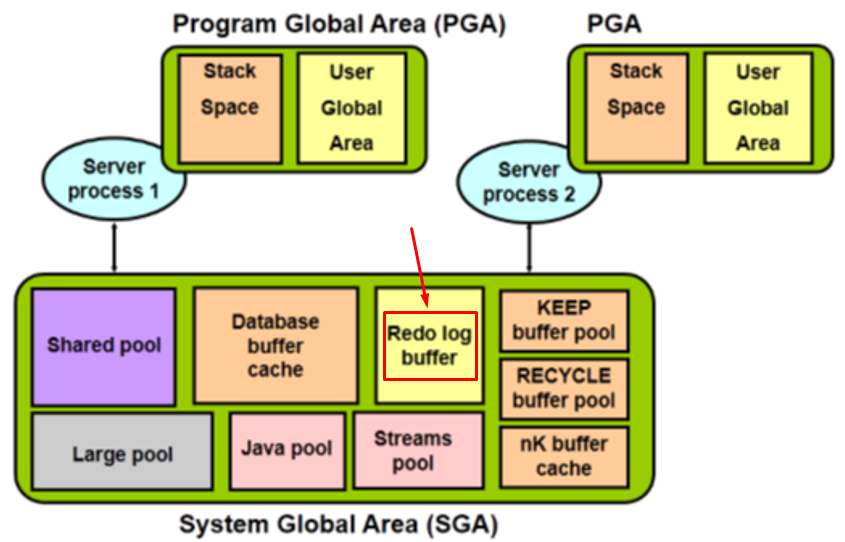
Tất cả thay đổi ở trên database kể cả do người dùng tạo ra hay do hệ thống tạo ra đều được ghi lại dưới dạng các véctơ thay đổi (change vector).
Các véctơ này mô tả sự thay đổi và được lưu ở trong Redo Log Buffer.
Như vậy, khi bạn chỉnh sửa 1 dữ liệu, dữ liệu đó ngoài việc bị đánh dấu là dirty buffer, còn sinh ra một vector mô tả thay đổi và được lưu trong Redo Log Buffer nữa.
Dữ liệu được lưu trữ ở Redo Log Buffer sẽ ở dạng quay vòng (circular buffer), tức là các vector cứ ngay ngắn xếp thành 1 hàng tại Redo Log Buffer chờ đến lượt được ghi xuống đĩa.
Ở cuối hàng đợi, các vector mới liên tục được bổ sung, do các thay đổi trong database được sinh ra liên tục.
Dữ liệu từ Redo Log Buffer được ghi xuống đĩa dưới dạng các redo log file. Các file redo log này có nhiệm vụ khôi phục lại database khi database instance bị shutdown đột ngột.
5. Tóm lại
Trên đây là ba phân vùng quan trọng nhất ở trên memory Chúng ta còn một số phân vùng khác ít quan trọng hơn như Java Pool, Large Pool, Stream Pool. Tuy nhiên, bạn chỉ cần tập trung ghi nhớ 3 phân vùng mà tôi đã nêu ở phần trên của bài viết. Sau này chúng ta sẽ còn phải làm việc với chúng rất rất nhiều.
Hẹn gặp lại các bạn vào bài viết sau.
Nguồn: https://dangxuanduy.com/
Hiện tại, tôi có tổ chức đều đặn các khóa học về quản trị Oracle Database, tôi sẽ để thông tin ở đây, để bạn nào quan tâm về lịch học cũng như chương trình học có thể theo dõi nhé.
KHOÁ DÀNH CHO NGƯỜI MỚI
KHÓA HỌC: QUẢN TRỊ ORACLE DATABASE THẬT LÀ ĐƠN GIẢN (ADMIN 1)
CÁC KHOÁ NÂNG CAO:
KHÓA HỌC ORACLE NÂNG CAO: QUẢN TRỊ KIẾN TRÚC MULTITENANT 12c
KHÓA HỌC ORACLE NÂNG CAO: QUẢN TRỊ HỆ THỐNG DATA GUARD
CÁC KHOÁ COMBO:
COMBO 1: ADMIN 1 + MULTITENANT 12c
COMBO 3: ADMIN 1 + MULTITENANT 12c + DATA GUARD
LỊCH HỌC:
Mời bạn xem tại đây: LỊCH HỌC CÁC LỚP ORACLE
ĐĂNG KÝ:
https://forms.gle/MtCAoRQFenP886y79
Hãy tham gia group “Kho tài liệu kiến thức database” để cùng học hỏi và chia sẻ nhé.
1 bình luận về “SGA trong Oracle là gì”